
ラスターとベクター解析、地形解析
今回は、ラスターとベクター解析について学んでいきましょう。地形解析を含めたラスターの解析を実習前半で行って、後半は、ラスターとベクターの両方を重ね合わせた解析を行います。
前回、「教師なし分類」について学びました。今回は「教師付き分類」から始めて、ラスター解析(マージ、バッファー、インターセクト)、さらに地形解析について学びます。
目標
1.教師付き分類について理解する。
2.地形解析を含めたラスター解析をできるようにする。
3.ラスターとベクターの両方のデータを使った解析をできるようにする。
演習が始めるために仮想ドライブの設定をしましょう。
最初に「教師付き分類」について実習を行いましょう。教師なし分類では、とりあえず、何でも分類しました。同じような「色」が付いている場所はすべて同じ分類カテゴリーになるように、あらかじめ決められた「数」に合わせて「勝手に」分類する手法でした。
教師なし分類の欠点は大きく2つです。
1.あらかじめ分類する「数」を決めて分類しなければならない。何個に分類するかは、その場所の土地利用の「種類」によって変わるのですが、あらかじめその場所を良く知ってないと正確に分類できません。
2.誤って分類する場所(誤分類)が多い。「影」となっている場所が「緑の濃い森林」に誤分類されることがある。似たような色のところが同じ分類結果になることがあるため、正確ではない。
そこで、教師付き分類を今回紹介いたします。「教師付き分類」とは、画像上の「色」とその場所に対応する土地利用分類カテゴリーを事前に「指定」し、「教えた」分類(教師付き)をもとに、全体を分類させる手法です。
この文章を読んでもよくわからないと思いますので、早速ソフトを使って理解してみましょう。
最初に、上のバーで、灰色の場所(何もツールがない場所)を右クリックしてください。ツールの一覧が以下のように表示されます。その中で「画像分類」というのを✓が付いていなければ、クリックして、ツールを開いてください。

上記のようなツールが、ソフトのどこかにありますので、捜してください。
教師付き分類に必要なデータを追加しましょう。Ex10_mosaic.zip(左をクリックして、データをダウンロードし、データの追加で追加しましょう。Lドライブにダウンロードしてください。
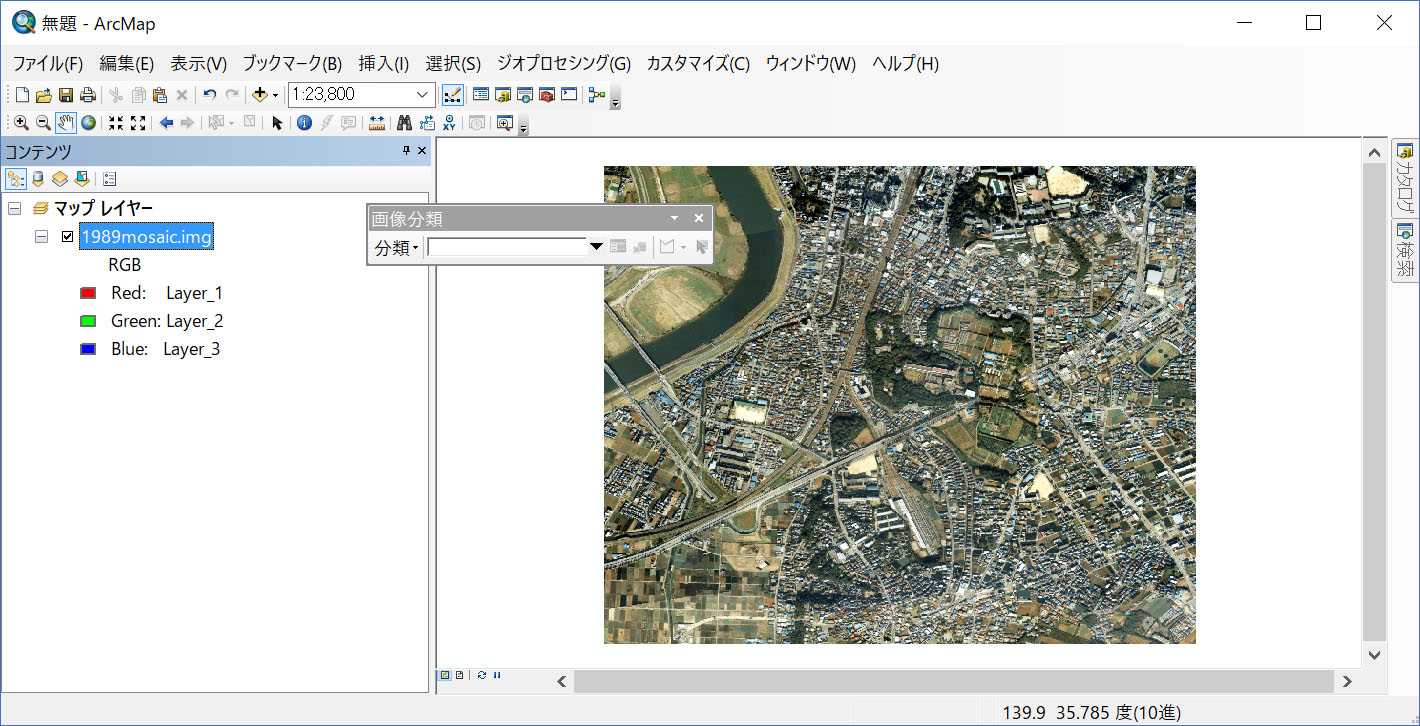 千葉大学 園芸学部の辺りをズームインして、土地利用(または土地被覆の様子)をあらかじめ定義しましょう。
千葉大学 園芸学部の辺りをズームインして、土地利用(または土地被覆の様子)をあらかじめ定義しましょう。
まずは、千葉大学 園芸学部に以下のようにズームインしてください。
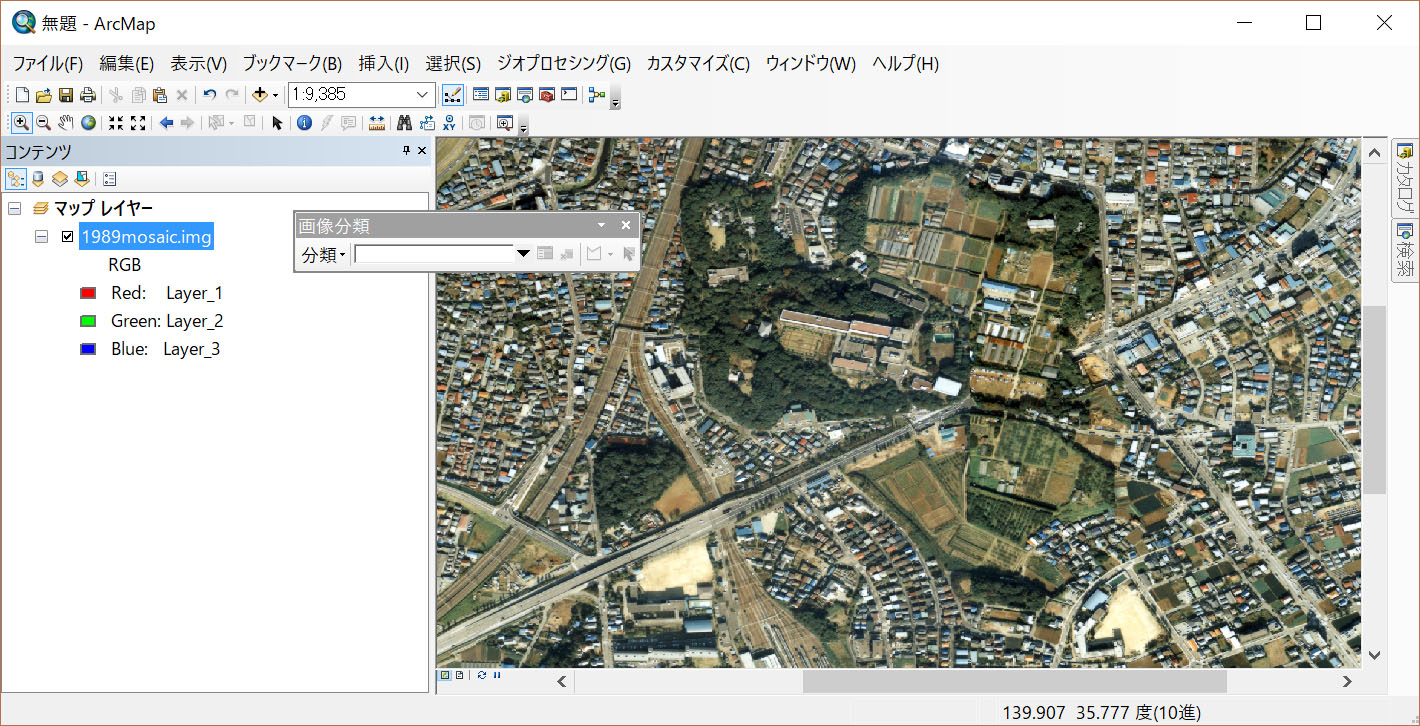
この画像から、事前にどのような土地利用があるかを理解しないといけません。この画像からわかる情報として
1.森林
2.住宅地
3.畑
4.道路
5.川(千葉大学 園芸学部周辺にはありませんが。)
これらを事前に指定して、分類のために教えてあげましょう。
順番に、まずは「森林」がどこにあるかを教えます。
![]()
上記のツールで対象としている画像が、「1989mosaic.img」が選ばれていることを確認して、一番左端にある「分類」をクリックしてください。
ツールの中にある ![]() のマーク (トレーニング サンプル マネージャー)をクリックし、以下のようにツールを開いてください。
のマーク (トレーニング サンプル マネージャー)をクリックし、以下のようにツールを開いてください。
![]() の中にある
の中にある ![]() をクリックして、森の場所を以下のように囲います。
をクリックして、森の場所を以下のように囲います。
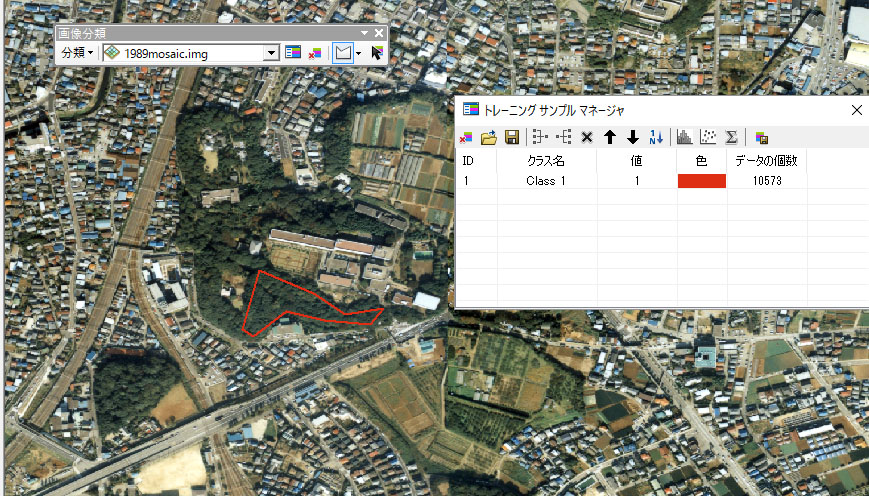
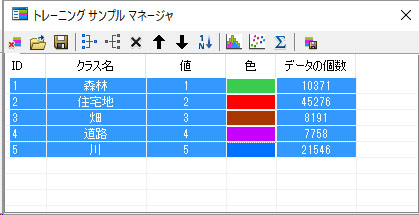
ここで2箇所修正します。トレーニングマネージャ上にある「クラス名」をClass 1から森林に書き変え、色を緑にしてください。
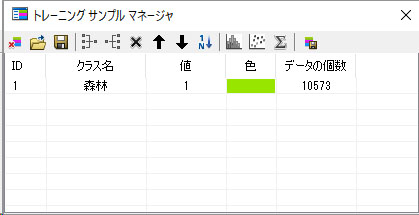
同様の作業を以下の4つの土地分類カテゴリーのために行ってください。トレーニングのサンプル場所は、ご自分で画像から判読して決めてください。私が設定した場所を以下に示します。クラス名と色も変えてください。
2.住宅地
3.畑
4.道路
5.川(千葉大学 園芸学部周辺にはありませんが。)
注意) 間違えたら、以下のようにトレーニングデータを削除してください。
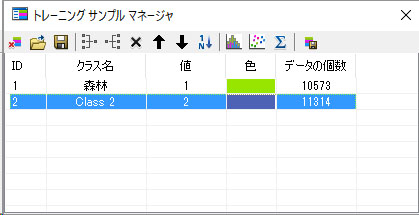
上記のように、間違えたサンプルの行をクリックして、上記の画面で左から6つ目にある ![]() をクリックすると、選択された行(トレーニングサンプル)が削除できます。
をクリックすると、選択された行(トレーニングサンプル)が削除できます。
以下が、私が設定したトレーニングのサンプル場所の例です。色や場所は好きなように設定していただいても良いです。現実的な色と合わせると、結果を理解する際にわかりやすいです。
また、サンプル場所を選ぶ際は、![]() の拡大、縮小のツールを使って、ズームイン、ズームアウトしてください。
の拡大、縮小のツールを使って、ズームイン、ズームアウトしてください。
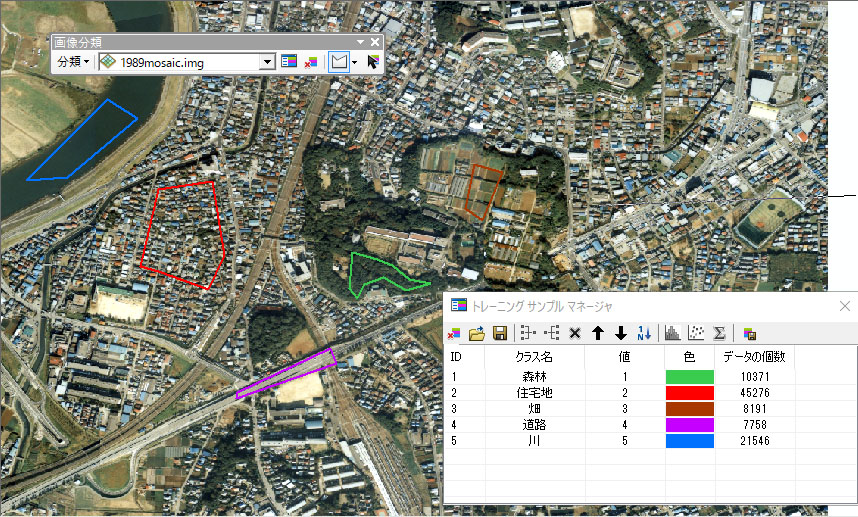
データ個数は、なるべく同じ数になるようにすると、結果がより正確になります(サンプル数に偏りがない方が良いです)。
また、選んだサンプルが、統計的にどれほど独立しているか?近いか?調べることもできます。
トレーニング サンプル マネージャ(上記)で、すべての行を選択し、
![]()
上記のツール(左はヒストグラム、右は散布図)をひとつずつクリックしてください。
まずは、以下のようにヒストグラムから、Layer1, Layer2, Layer3は画像のRGBを示しており、どの色のサンプルがどれほど色として似ているか?独立しているか?示しております。
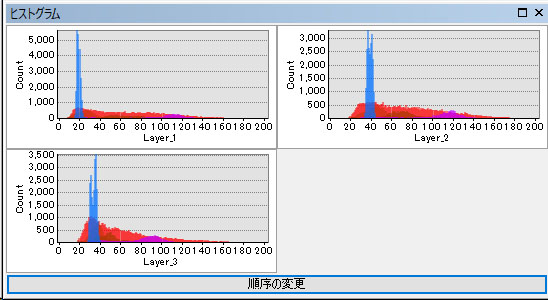
この結果から、赤色(住宅地)がどの分類ともオーバーラップしていることがわかります。誤分類可能性があることをあらかじめ示しております。
つぎに、散布図をクリックしてください。

Layer1, Layer2, Layer3はそれぞれRGBですので、色別(色同士)の関係を散布図は表しており、紫色は非常に強い相関関係があり、似通っているため、紫色(道路)は、3つの色を利用しても、1つの色を利用しても分類結果に違いが生じないことを表しています。また、赤色(住宅地)が紫(道路)を覆うような関係であることから、住宅地の中に道路が含まれていることもわかります。含まれているというのは、誤分類が生じやすいため、本来ならばもっと細かくサンプルする必要があることを示してます(住宅地と道路をより詳細にポリゴンで分けた方が良い)。
ここまでできたら、皆さんが定義した土地分類カテゴリーに従って、画像全体を分類してくれますので、以下のようにやってみましょう。
![]()
「ぱっと」早急に答えを見たい人は、上記のツールに戻って、分類-> 「対話的な教師付き分類」をクリックしてください。結果をすぐに表示してくれます。

川が少し緑になってますよね?川がすべて青になるはずが、緑を含んでいるのは、濃い緑と濃い青が混同してしまった結果です。サンプルをより正確に選べば、こうしたエラーが解決できます。
教師付きの良い点は、このようにエラーが出た時に、マニュアルである程度直せるところです。教師無しでは、こうして直すことができないため、教師付きの方が好まれます。
結果を保存したい場合は、以下の2つの手順で解析をしてください。
1.シグナチャファイル というファイルを作成し、トレーニングデータを保存しないといけません。そのために、以下のトレーニング サンプル マネージャの一番右のツールをクリックしてください。
 (← この欄の一番右のツールをクリック)
(← この欄の一番右のツールをクリック)
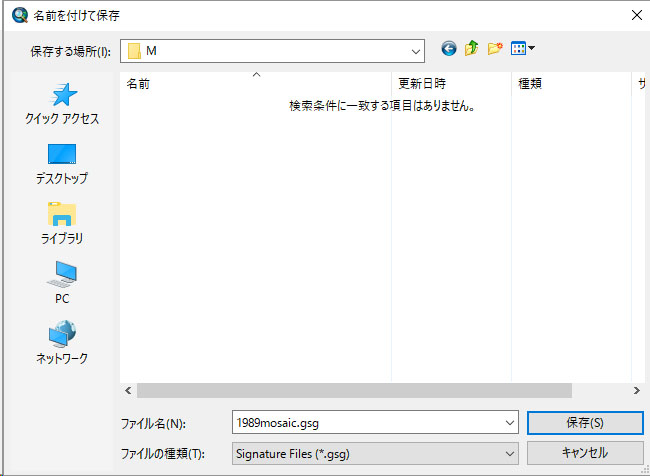
上記のように、1989mosaic.gsg というファイル名で、何も変更しないで、Mドライブに保存してください。
その後、
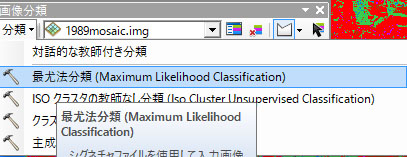
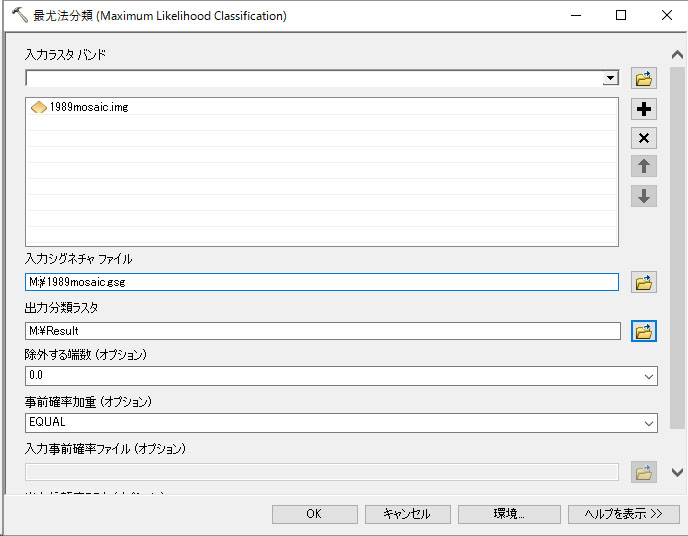
2.上記のツールから、分類-> 最尤法分類 を使って解析してください。
入力ラスタ バンドは、1989mosaic.img (最初の空中写真)
入力シグナチャ ファイルは、Mドライブに先ほど保存したシグナチャファイルを指定
出力ラスタ ファイルは、MドライブにResultというファイル名で保存
クリックOK
結果で表示される色は変わりますが、同じ結果が自動で追加されます。番号と対応して結果表示されます。
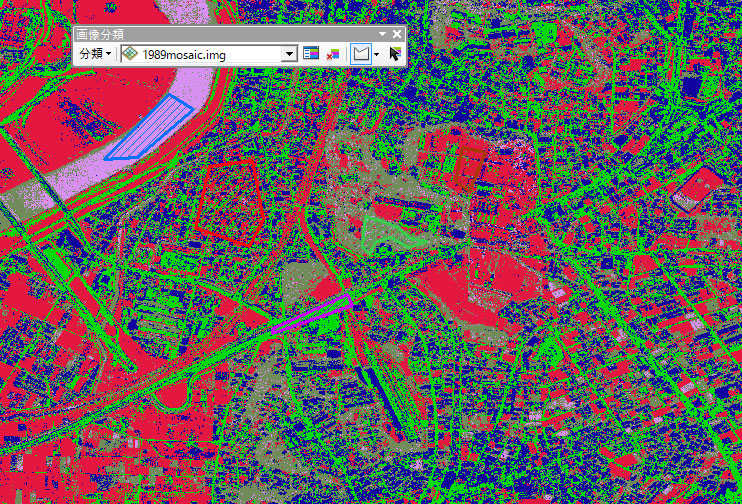
ここままで、教師付き分類は終わりです。
「よくがんばってくれました。ありがとう!後半も引き続きがんばって」

(重要) ベクターデータに使った解析ツールは、ラスターデータには使えません。ベクター解析で特に重要な3つのツールに対応するラスター解析のツールを最初にご紹介します
1.ベクター解析で使ったマージは、ラスターではMosaic(モザイク)を使います。
2.ベクターのバッファーは、ラスターでは、Euclidean Distance (ユークリッド距離)を使います(今回実習します)。
3.ベクターのインターセクトは、ラスターでは、Tabulate Area (クロス集計)を使います(今回実習します)。
今回扱うデータは、ココ(50MBあるため、ダウンロードに時間がかかるかもしれません。)からLドライブにダウンロードしてください。圧縮ファイル(zipファイル)をLドライブで解凍してください。まずは、ラスターのバッファーを使ってみよう。
土地利用図から情報を取得
ダウンロードしたデータからlu1974, lu1984, lu1994の3つのラスターレイヤーをデータ追加で追加してください。
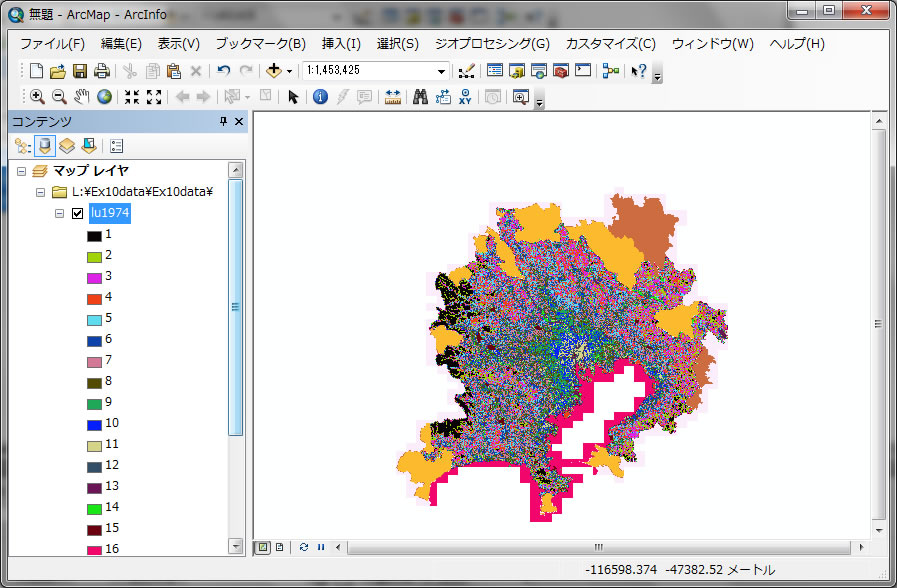
左のウィンドウで、各番号が違う配色になってます。各番号は、何を意味しているのでしょうか?下の対応表をみてみましょう。
土地利用分類と分類コード対応表(全部読まなくて良いです。
「コード」と「大分類」をざっと掴んでください。)
| コード | 土地利用分類 | 定義 | ||
|---|---|---|---|---|
| 大分類 | 中分類 | 小分類 | ||
| 01 | 山林・農地等 | 山林・荒地等 | 樹林地、竹林、篠地、笹地、野草地(耕作放棄地を含む)、裸地、ゴルフ場等をいう。 | |
| 02 | 農地 | 田 | 水稲、蓮、くわい等を栽培している水田(短期的な休耕田を含む)をいい、季節により畑作物を栽培するものを含む。 | |
| 03 | 畑・その他の農地 | 普通畑、果樹園、桑園、茶園、その他の樹園、苗木畑、牧場、牧草地、採草放牧地、畜舎、温室等の畑及びその他の農地をいう。 | ||
| 04 | 造成地 | 造成中地 | 宅地造成、埋立等の目的で人工的に土地の改変が進行中の土地をいう。 | |
| 05 | 空地 | 人工的に土地の整理が行われ、現在はまだ利用されていない土地及び簡単な施設からなる屋外駐車場、ゴルフ練習場、テニスコート、資材置場等を含める。 | ||
| 06 | 宅地 | 工業用地 | 製造工場、加工工場、修理工場等の用地をいい、工場に付属する倉庫、原料置場、生産物置場、厚生施設等を含める。 | |
| 07 | 住宅地 | 一般低層住宅地 | 3階以下の住宅用建物からなり、1区画あたり100平方メートル以上の敷地により構成されている住宅地をいい、農家の場合は、屋敷林を含め1区画とする。 | |
| 08 | 密集低層住宅地 | 3階以下の住宅用建物からなり、1区画あたり100平方メートル未満の敷地により構成されている住宅地をいう。 | ||
| 09 | 中高層住宅地 | 4階建以上の中高層住宅の敷地からなる住宅地をいう。 | ||
| 10 | 商業・業務用地 | 小売店舗、スーパー、デパート、卸売、飲食店、映画館、劇場、旅館、ホテル等の商店、娯楽、宿泊等のサービス業を含む用地及び銀行、証券、保険、商社等の企業の事務所、新聞社、流通施設、その他これに類する用地をいう。 | ||
| 11 | 公共公益施設用地 | 道路用地 | 有効幅員4m以上の道路、駅前広場等で工事中、用地買収済の道路用地も含む。 | |
| 12 | 公園・緑地等 | 公園、動植物園、墓地、寺社の境内地、遊園地等の公共的性格を有する施設及び総合運動場、競技場、野球場等の運動競技を行うための施設用地をいう。 | ||
| 13 | その他の公共公益施設用地 | 公共業務地区(国、地方自治体等の庁舎からなる地区)、教育文化施設(学校、研究所、図書館、美術館等からなる地区)、供給処理施設(浄水場、下水処理場、焼却場、変電所からなる施設地区)、社会福祉施設(病院、療養所、老人ホーム、保育所等からなる施設地区)、鉄道用地(鉄道、車両基地を含む)、バス発着センター、車庫、港湾施設用地、空港等の用地をいう。 | ||
| 14 | 河川・湖沼等 | 河川(河川敷、堤防を含む)、湖沼、溜池、養魚場、海浜地等をいう。 | ||
| 15 | その他 | 防衛施設、米軍施設、基地跡地、演習場、皇室に関係する施設及び居住地等をいう。 | ||
| 16 | 海 | 海面をいう。 | ||
| 17 | 対象地域外 | |||
| 18 | (ダミーコード) | (1979年(第2時期)データ作成時に対し1984年(第3時期)データ作成時に対象地域が拡大されたことに伴い、1974年 (第1時期)データ及び1979年(第2時期)データにおける拡大部分に土地利用データが無いため、便宜上入れたコード) | ||
| 19 | (ダミーコード) | (1974年(第1時期)データ作成時に対し1979年(第2時期)データ作成時に対象地域が拡大されたことに伴い、1974年(第1時期)データにおける拡大部分に土地利用データが 無いため、便宜上入れたコード) | ||
ラスターのバッファー
ベクターデータを使った演習では、Buffer(バッファー)というツールを使って、線や点の周りにポリゴンを作ることができました。Bufferというツールは、ベクターデータのみに使うことができます。では、ラスターデータに対するバッファーをこれから使ってみましょう。
挿入から、「新しいデータフレーム」を追加して、lu1994のみを新しいデータフレームに移動しましょう。
ここでまず、例題を設定します。「河川や水(カテゴリー14番)のところから100m以内にある公園(カテゴリー12番)の面積はどれくらいありますか?」
属性テーブルを開いて、河川や水のある場所(14番、VALUEフィールドを用いること!)の行をクリックしてください。画面上に水のある場所が青く選択されることがわかります。
ラスターのバッファーを使うには、検索ということで、Distanceと書いて捜してみてください。Euclidean Distance(ユークリッド距離)というツールが見つかります。 ツールをクリックして開いてみましょう。
以下のように設定してください。入力ラスタを lu1994として、出力距離ラスタをMドライブからbufferという名前で保存してください。出力セルサイズは、このlu1994のラスタのセルサイズが自動で取り込まれます。
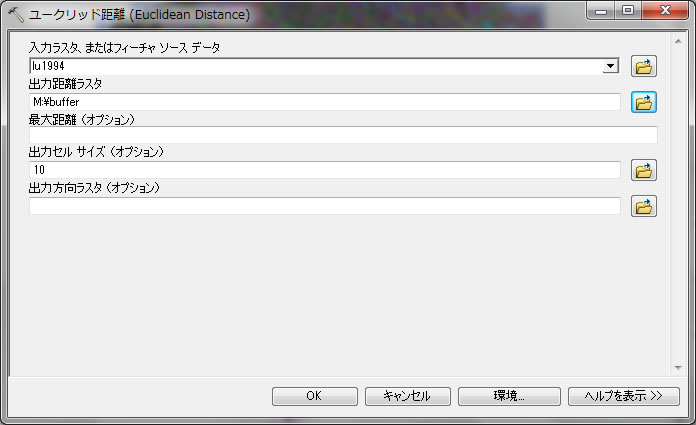
最大距離を空欄にしておくと、最大距離の設定のないバッファーを作成します。以上の設定でクリックOKすると、以下の結果が表示されます。
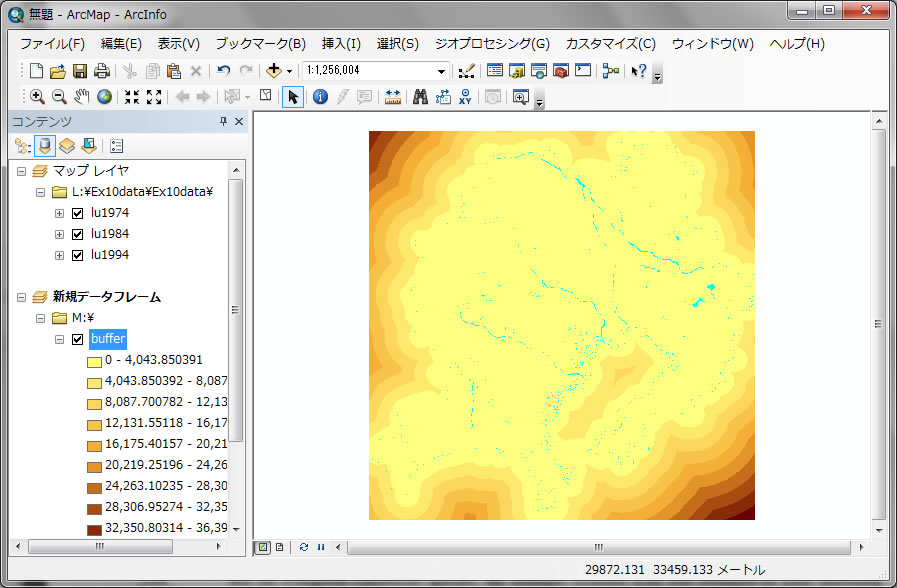
解析を続ける前に、このラスターのセルサイズと距離単位を確認しておこう。
bufferを右クリックしてプロパティを開いて、
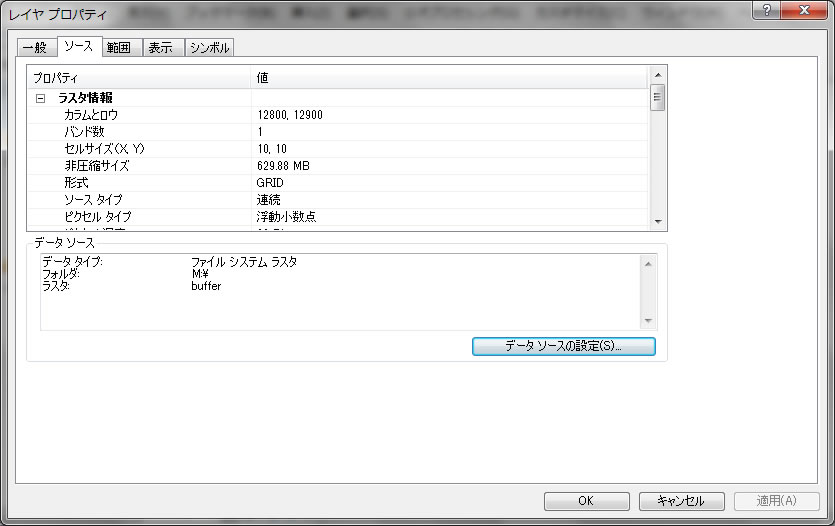
セルサイズが10 x 10で、
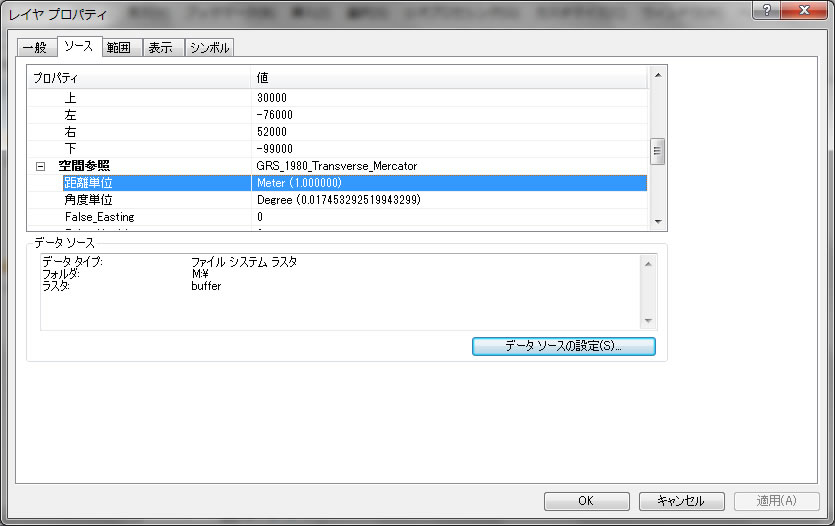
距離単位がメートルです。
では、100m以内のバッファー範囲を把握するためラスタ演算 を使いましょう。検索から raster calculator を検索してツールを開こう。
左上にあるbufferをダブルクリックして、下の式を下記のように記入します。出力ラスタは、Mドライブへ行き、buffer100mというファイルを作成してください。
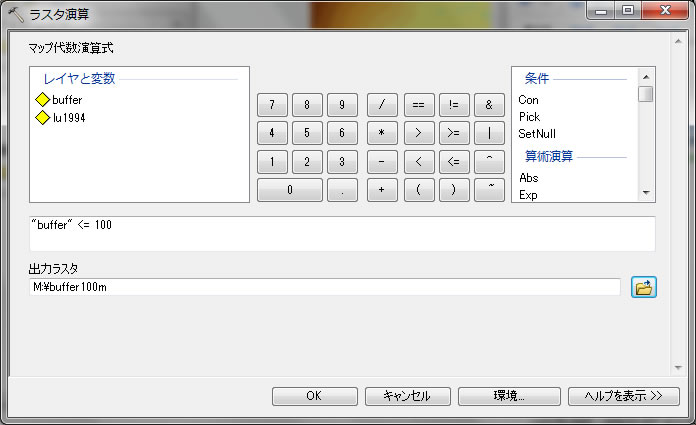
上記のように設定できたら、クリックOK。結果は以下のように表示されます。
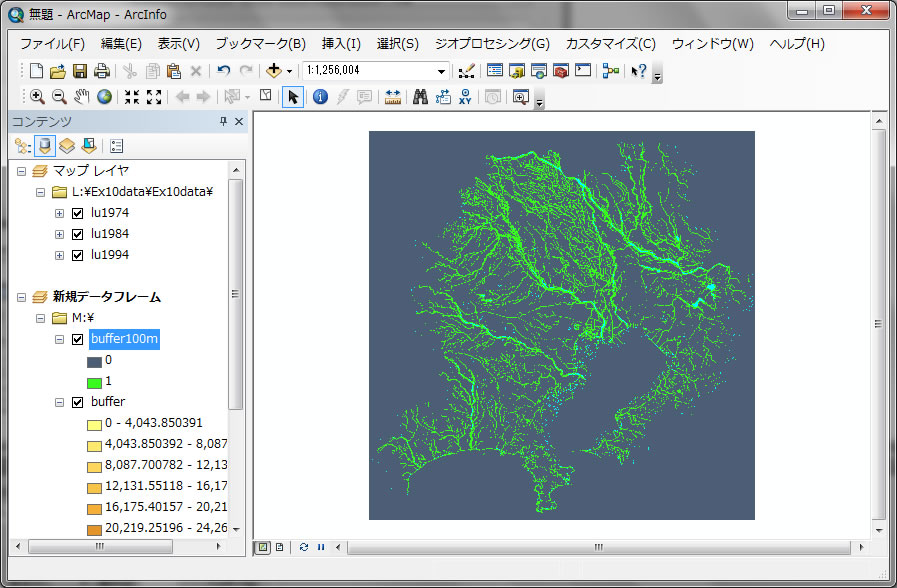
buffer100m というレイヤーで、1になっている場所が100m以内で、0になっている場所がそれ以外です。ラスター演算は、記入した条件式が合っているところは1となり、条件に合わない場所は0と出力されますので、覚えておいてください。
1の場所だけ土地利用を切り出す方法はいろいろあります。
1.ラスタ演算を用いて掛け算して切り出す方法、
2.「Extract by Mask」というツールを使って先ほど作成したbuffer100mファイルを「マスク」として使い、切り出す方法、などなど。
2つのラスター間で、重なり合う場所の面積を把握するには、ベクターだったらIntersect(インターセクト)というツールが使えますが、ラスターデータにはIntersectというツールは使えません(Intersectはベクターデータしか扱えません)。そこで、ラスターデータ間の重ね合った場所だけを対象に計算するツールとして、Tabulate Area (クロス集計)を今回は用います。
注意)クロス集計を行う前に、最初に選択した場所があるので、選択セットの解除をしてください。lu1994のデータを右クリックして、属性テーブルを開き、「選択セットの解除」をしてください。選択を解除しないと、選択したところだけ解析してしまいます。
Tabulate Area (クロス集計)
検索から、tabulate と入れてクロス集計ツールを見つけて開いてください。
以下のように入力してください。
入力ラスタをlu1994とし、ゾーンフィールドをValue
もう一つの入力ラスタはbuffer100mとして、ゾーンフィールドをValue
出力テーブルはMドライブでResult1994というファイル名にしてください。
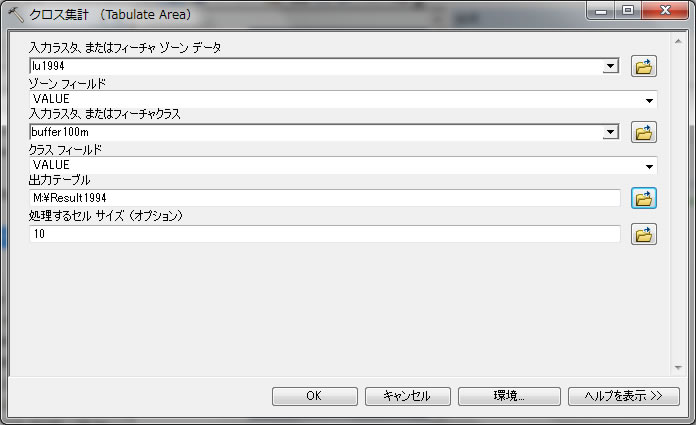
上記の様に入力し、クリックOK。出力されるテーブルを開いてください。
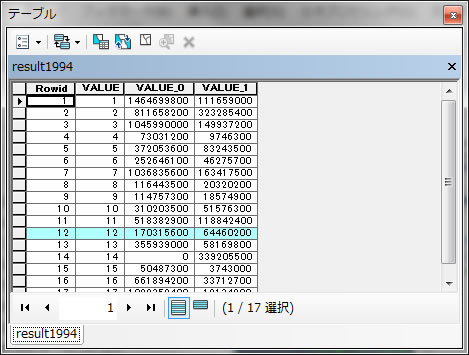
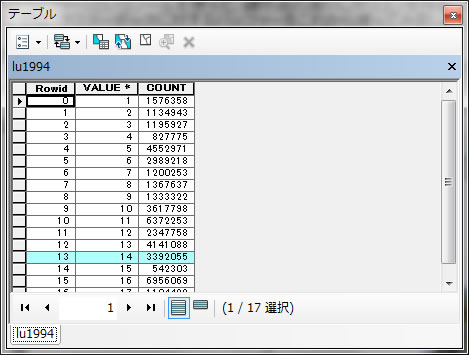
このテーブルの意味は、縦軸が最初にツールに入力した1994年の土地利用カテゴリー番号を表し、横軸があとに入力した川から100m以内かどうかを0と1で表したラスターを表してます。
表の読み方としては、lu1994から公園(カテゴリー12番)の行を最初に捜して、そこで、縦軸のVALUE_0とVALUE_1と重なるところに書いてある数字を読みます。川から100m以内を表すVALUE_1が交わるところに64460200という数字が記載されていることがわかります。川から100m以内にある公園の総面積が64460200 m2 という意味です。
このように、ラスター同士重なり合う場所を計算する際、Tabulate Area (クロス集計)のツールを用いましょう。 ツールを用いれば自分で面積を計算することなく、重なり合った場所の面積を自動で計算し、表示します。ただ、注意しないといけないのは、入力するラスターデータは、カテゴリー(整数値で表すデータ)でなければなりません。少数点が入ったデータでクロス集計するとクラッシュします。
ここまでの実習で、ラスターのバッファーやインターセクトの仕方を学びました。後半は、ラスター解析である地形解析を学びましょう。
地形解析 (slope, aspect, hillshade)
ラスター解析のひとつに地形解析があります。 地形を把握するのに、傾斜角(slope)、傾斜方向(aspect)など計算しないといけません。これらをGISを用いれば自動で計算することができます。まず、新しいデータフレームを挿入して、LドライブのChibaフォルダーからdem50mを追加してください。これは標高を表すラスターデータです。
この標高値のデータから傾斜を求めましょう。検索からslopeと入力してツールを検索してください。3DAnalystのでもSpatial Analystのでもどちらでも良いです。
入力ラスタは dem50m
出力ラスタは Mドライブにslopeと名前を付けて保存してください。
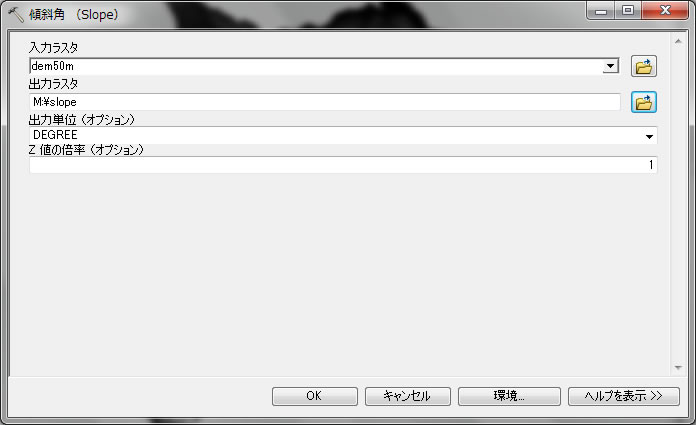
クリックOKすると
千葉県内の傾斜角度分布が表示されます。このデータから、千葉県の南部に傾斜角度が急な地域が分布していることがわかります。
次に傾斜方向を表示させてみましょう。検索から aspect と入力してください。
入力ラスタを dem50mとして、出力ラスタをMドライブのaspectとします。
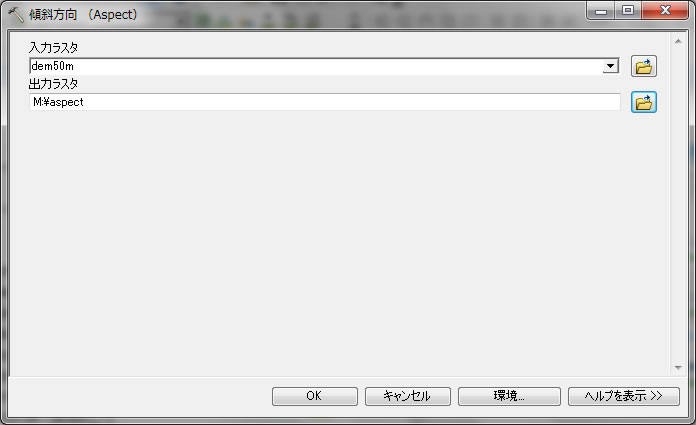
クリックOKをすると。
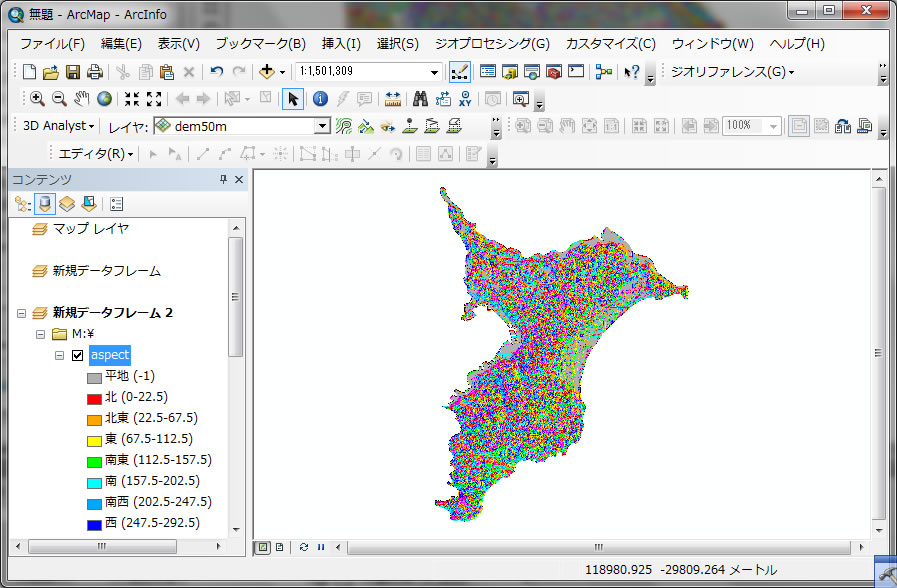
この様に、傾斜方向が計算され表示されます。どの方角に各斜面が向いているかは、左側のウィンドウをみると、方角が記載されているためわかりやすいです。
ここで、ラスターからベクターに変換する仕方を学びましょう。
上の斜面方向(aspect)の結果から南向き斜面だけを切り出してみましょう。右のウィンドウで、南向き斜面は、157.5から202.5度であることがわかります。その範囲の斜面方位を抜き出しましょう。
ラスター演算 を使って、157.5から202.5度だけを切り出しましょう。検索でraster calculatorと入力してツールを開きます。
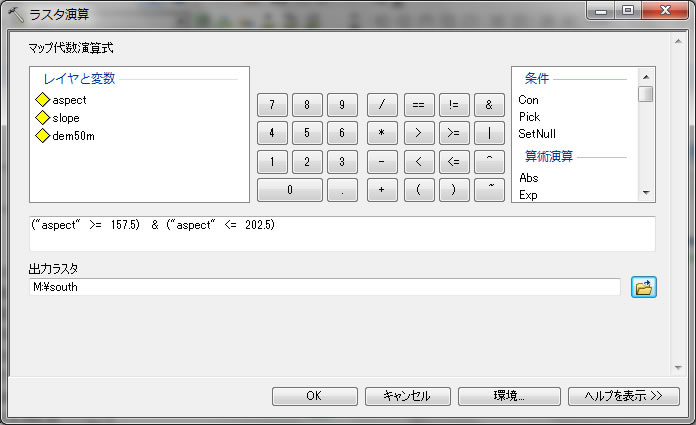
上記のように入力し、出力はMドライブでsouthという名前で出力してください。エラーがなければ、クリックOKすると。。。
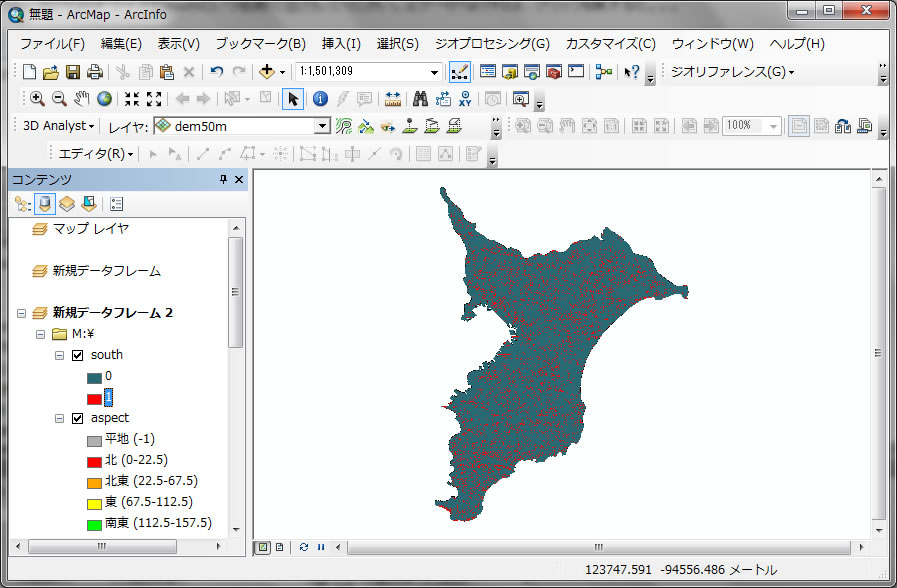
southというレイヤーが追加されて、0と1のデータが表示されていることがわかります。1は、南向き斜面、0はそれ以外です。ここまで準備できたら、ラスターからベクターに変換しましょう。ArcToolBoxを開いて、変換ツール -> ラスターから変換 -> ラスタ -> ポリゴン をクリックしてください。
入力ラスタをsouth, 出力フィーチャをsouth.shpとします。
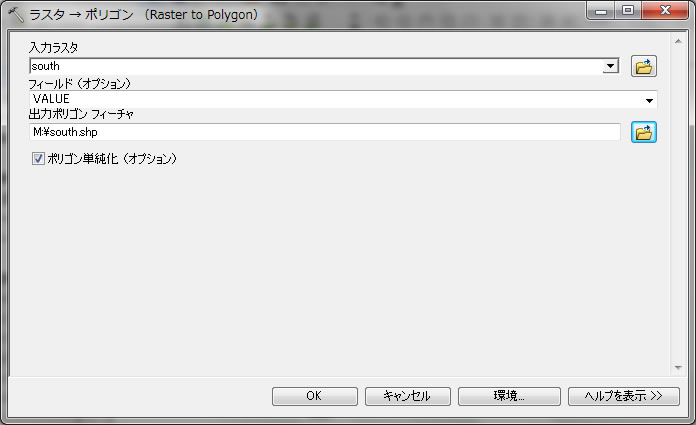
ポリゴン単純化は今回チェックを入れたままにしますが、チェックをはずすと角張った結果が表示されます。後ほどチェックを入れるのと入れないのでどのように結果が異なるか?試してみてください。クリックOKすると。。。
「ちょっと時間かかるかもしれないけど、待ってね。」
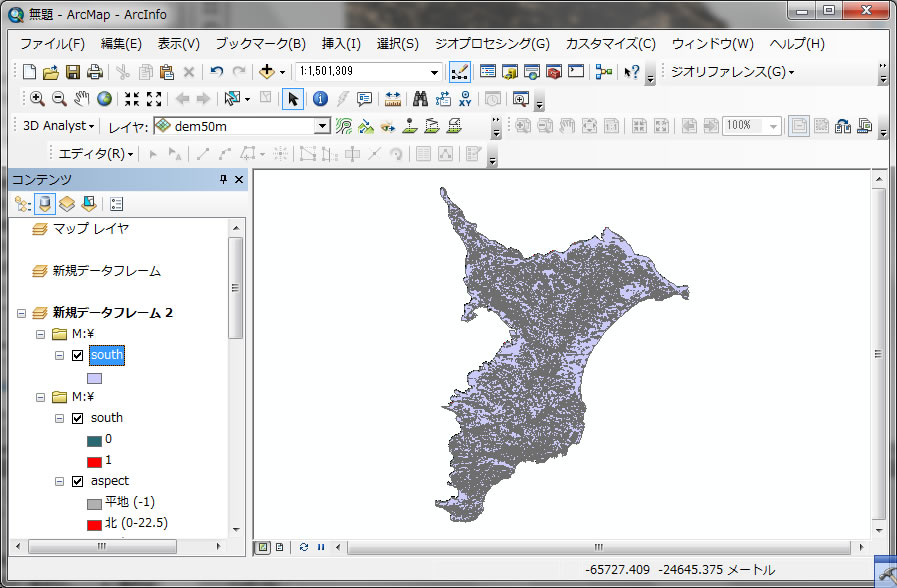
このように、ラスターデータを整数値にすれば(上記のやり方で0、1にする等)ベクターに変換できます。ベクターに変換できれば、インターセクト等のベクターしか使えないツールが使えるようになります。
「なーるほど。やったね!」
今日最後に、Hillshade(陰影起伏)を用いて地形の凹凸を影を付けてかっこいい図を作成し、表示してみましょう。検索からhillshadeを捜して開いてください。
入力ラスタにdem50m
出力ラスタは、Mドライブでhillshadeというファイルで出力してください。
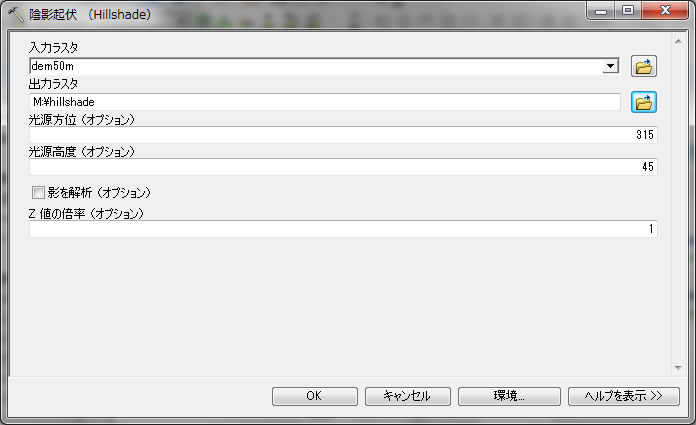
設定できたら、クリックOK。
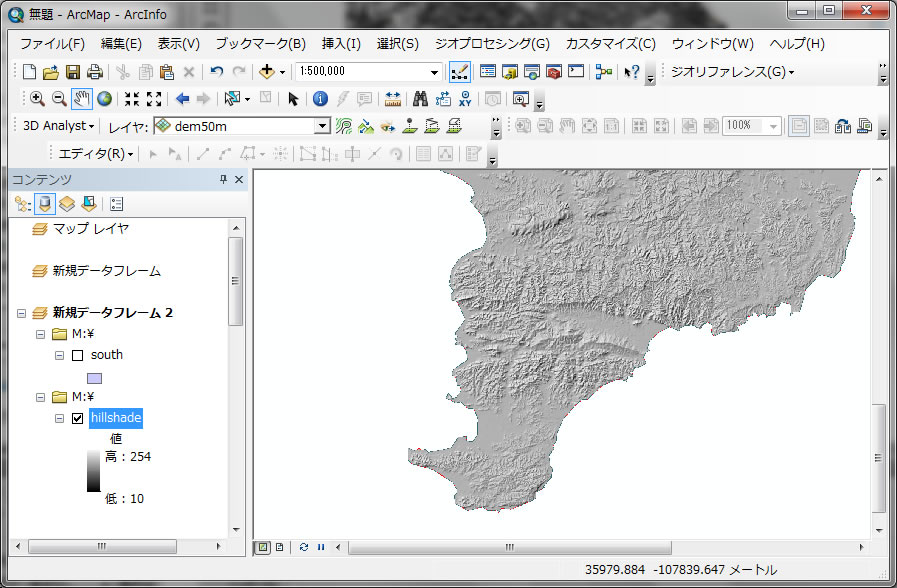
陰影を付けたことで、千葉県の地形が、より鮮明に表示されました。プレゼンで発表する際、地形の起伏を表すのによくこのツールを用います。
ラスターとベクターの両方のデータを使った解析を行います。
新たに新規データフレームに追加してください。Lドライブ、Ex10dataのフォルダー内の BigTree.shp(千葉県の巨木位置の点データ) と dem50m(標高図)をChibaフォルダからデータの追加してください。
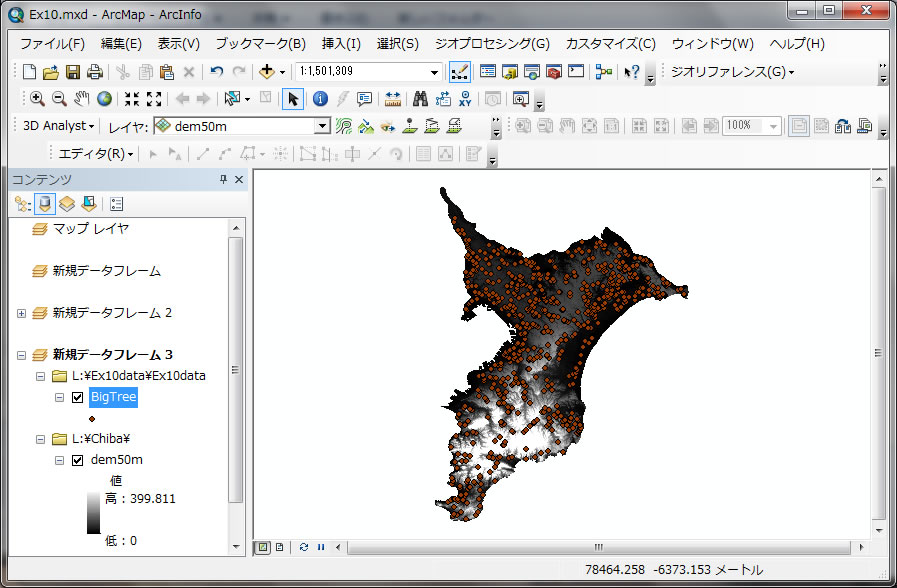
BigTree.shp は千葉県内の大きい木の位置を示しています。各場所の標高値をDEM (標高図)から得ましょう。
標高値の取得
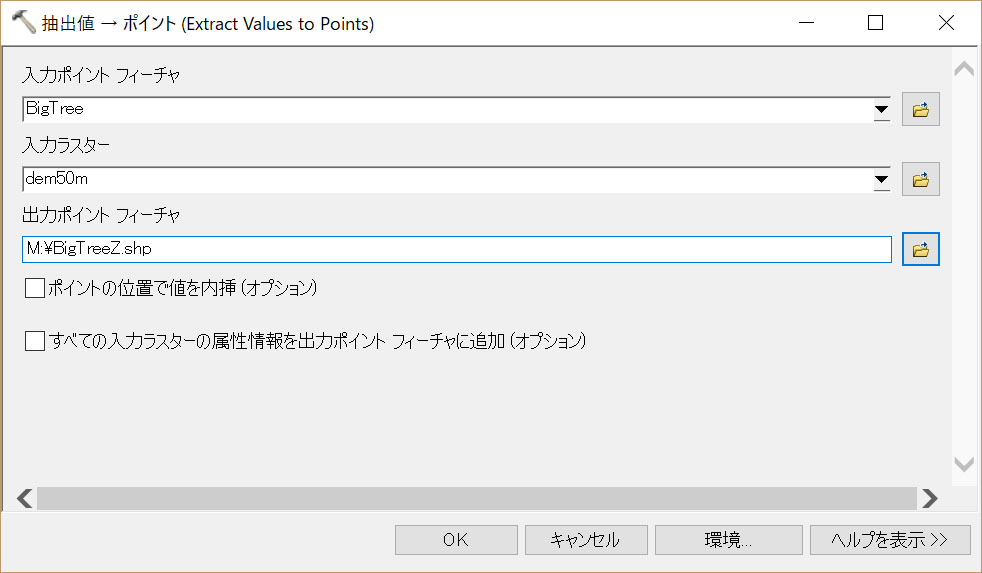
BigTree.shpはベクターで、dem50mはラスターです。ベクターファイルとラスターを合わせて計算するには、「抽出値->ポイント」 というツールを使用します。検索から 抽出値 と入れて捜すとツールが見つかります。
入力ポイント フィーチャに BigTreeを入れて、
入力ラスターにdem50mを入力し、
出力ポイントフィーチャに、Mドライブに、BigTreeZ.shp というファイルを新たに作成してください。
どこに標高の情報があるのでしょうか?新たに追加されたBigTreeZの属性テーブルを開いてみましょう。一番右にあるフィールド(列)にRASTERVALUという列が追加され、各巨木の標高値が追加されました。
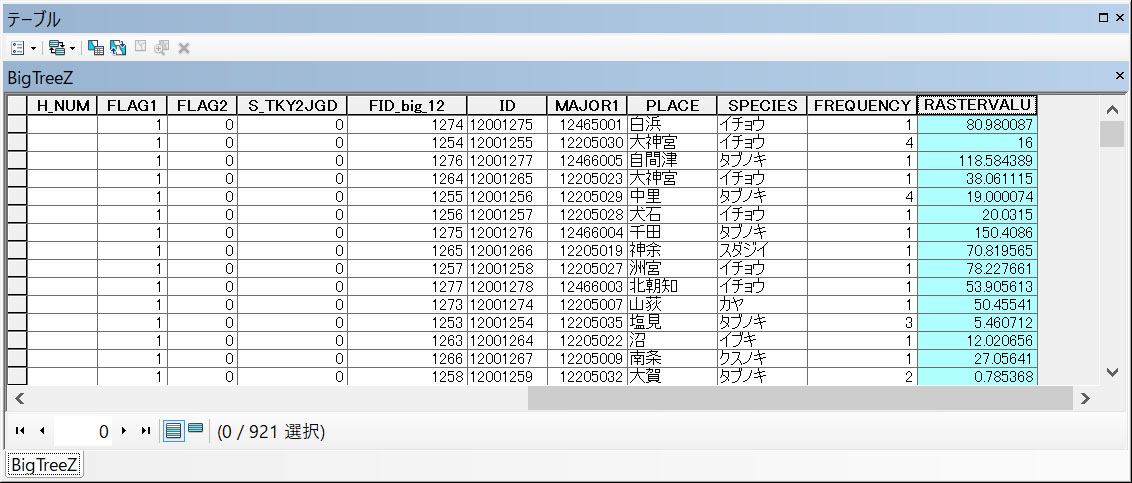
属性テーブルの一番右に標高値の入ったフィールドが追加されています。ベクターデータ(BigTree)の位置情報に基づいてラスターデータ(標高値)を得ることができました。
今回は点からラスター値を抽出しましたが、ポリゴンからラスターを抽出することもできます。各市町村の平均標高を計算してみましょう。今あるデータフレームに、Chiba_boundaryをデータ追加してください。
Chiba_boundaryは市町村境界のポリゴンです。各ポリゴン内の平均値を得たいため、今回はZonal Statisticsというツールを使用します。検索からzonal と入れて検索してください。Zonal Statistics as Table というツールをクリックして開いてください。
入力ラスタをChiba_boundaryとして、ゾーンフィールドをCITY1を選んでください。CITY1は、各市町村の名前が入っています。入力ラスタをdem50mとしてMドライブにaveDEMという名前のテキストファイルとして結果を出力させるようにします。
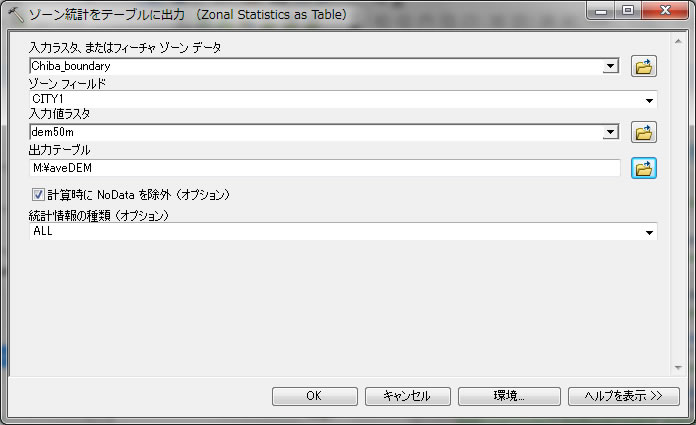
上記の様に設定して クリックOK。
aveDEMという新たに加わったテーブルを右クリックしてテーブルを開くと
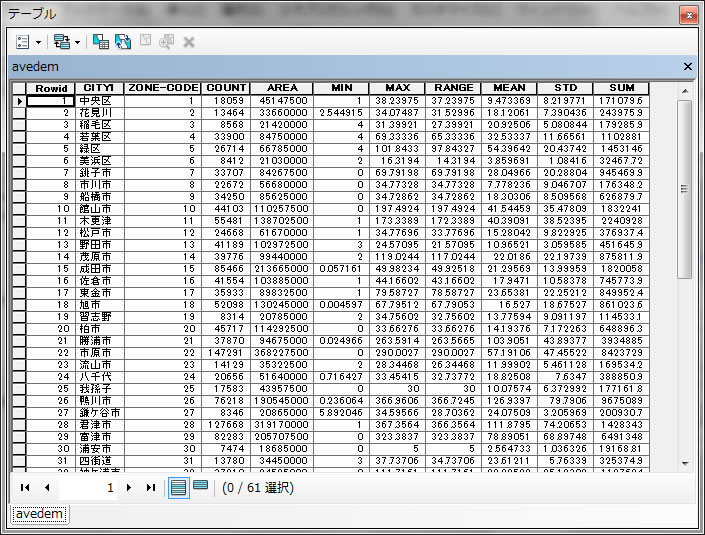
という一覧表が出てきます。これは各ポリゴン(市町村)の面積、そのポリゴン内での標高値の最小、最高、平均、標準偏差、合計値を計算してくれました。
今日最初に行ったポイントから標高値を抽出する手法では、1つの点に対して1つのラスタ セル値が対応するため、各点に対して1つの標高値が結果として出てきました。ポリゴンの場合は、ポリゴン内では様々な標高値が対応するため、標高値の統計(平均等)が結果として出力されました。その違いを理解しておきましょう。
今回のBigTreeは巨木のある位置です。巨木のある場所の標高値を把握することができました。この様にラスターとベクターを重ね合わせて、データ形式の違いを超えて解析ができるようになりました。
今日の実習はここまでです。Cドライブにあるworkplaceフォルダーを削除して、必要なら持ってきたメモリーにファイルをコピーして帰りましょう。コンピュータをシャットダウンすることも忘れずに!千葉大環境ISOにご協力を。Cドライブの他のフォルダーを削除しないように!コンピュータに必要なファイルを削除したら、利用委員の規約より厳重に罰せられます。気をつけてくださいね。
「お疲れ様、また会おうね。バイバ~イ」